RAG Hallucination
Overview
Retrieval Relevance represents the relevance of the documents retrieved from the vector database using the embedding model for each query. To measure the retrieval relevance, Dynamo AI generates a relevance label with an LLM. Studies have shown the effectiveness of LLMs as reference-free evaluators for tasks such as content relevance.
Response Faithfulness represents the faithfulness of model generated responses to the retrieved documents. Dynamo AI uses a natural language inference (NLI) model, which labels a (context, response) pair as either entailing, contradicting, or neutral, with corresponding scores. Entailing indicates that the response logically implies the content in the document while contradicting indicates otherwise, and neutral indicates that no logical relationship can be drawn between.
Response Relevance represents the relevance of model-generated responses to the query. To measure the response relevance, Dynamo AI generates a Response Relevance Score.
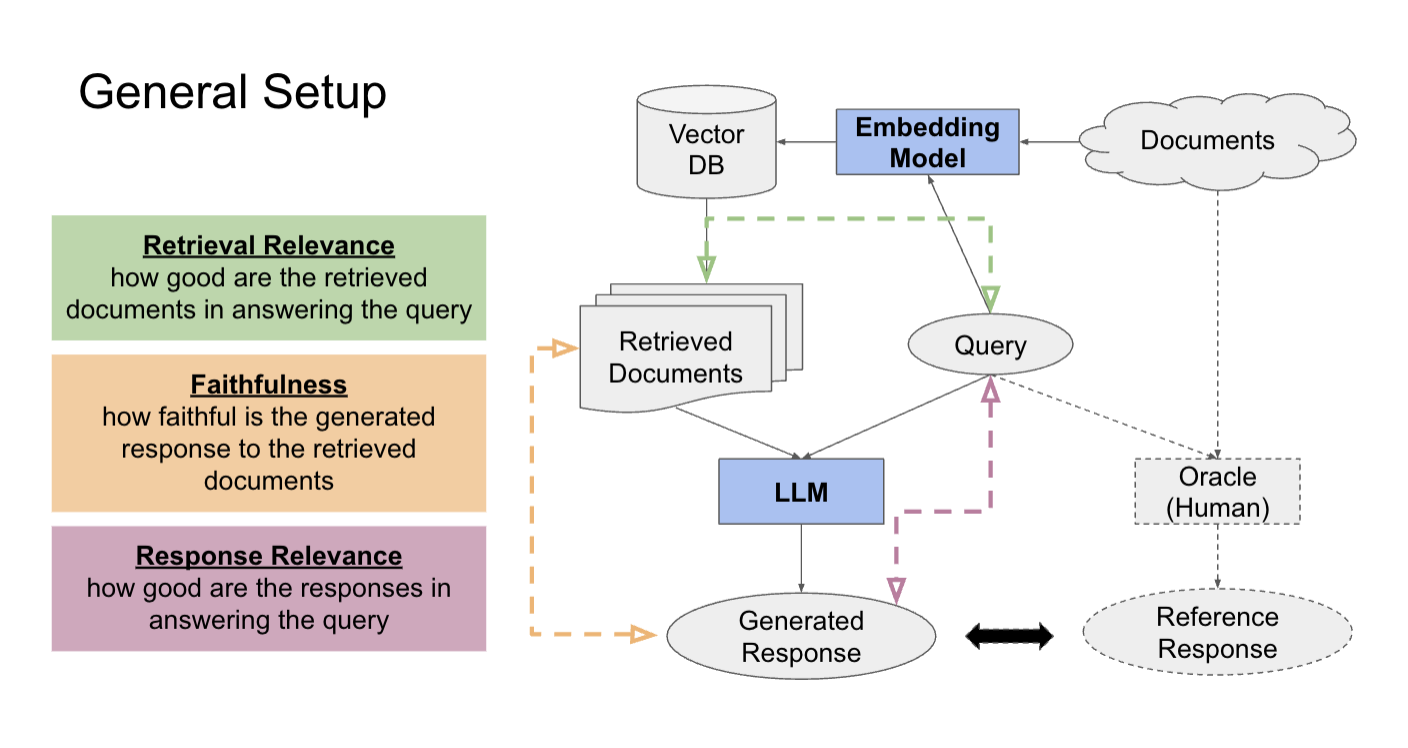
Metrics
Retrieval Relevance Score: This metric is computed by prompting an LLM to evaluate the sufficiency of the content in the retrieved documents to answer a given user query. For each query, DyanmoFL computes the relevance score against the top document retrieved from the vector database. Based on this score, each (query, retrieved document) pair will be classified as either positive (relevant) or negative (not relevant). A negative classification indicates that the retrieved document may not contain the key information required to answer the given query.
Response Faithfulness Score: To measure the response faithfulness, Dynamo AI uses a Logical Consistency score, relying on a Natural Language Inference (NLI) model. Dynamo AI specifically runs the NLI model over each combination of sentence pairs from retrieved contexts and the generated response. This enables Dynamo AI to then retain the highest entailment score for a given generated response sentence. Finally, Dynamo AI takes the mean of all the maximum entailment scores for each sentence in the response to provide an aggregate score for the full response generated. Based on this score, each (set of retrieved documents, response) will be classified as either positive (no issue) or negative (response potentially missing/contradicting some key information in the retrieved documents).
Response Relevance Score: This metric is computed by prompting an LLM to generate a score between 0 and 1 that indicates how relevant the generated response is to the question. Based on this score, each (query, response) will be classified as either positive (relevant) or negative (not relevant). A negative classification indicates that the response may not contain the information that answers the query.